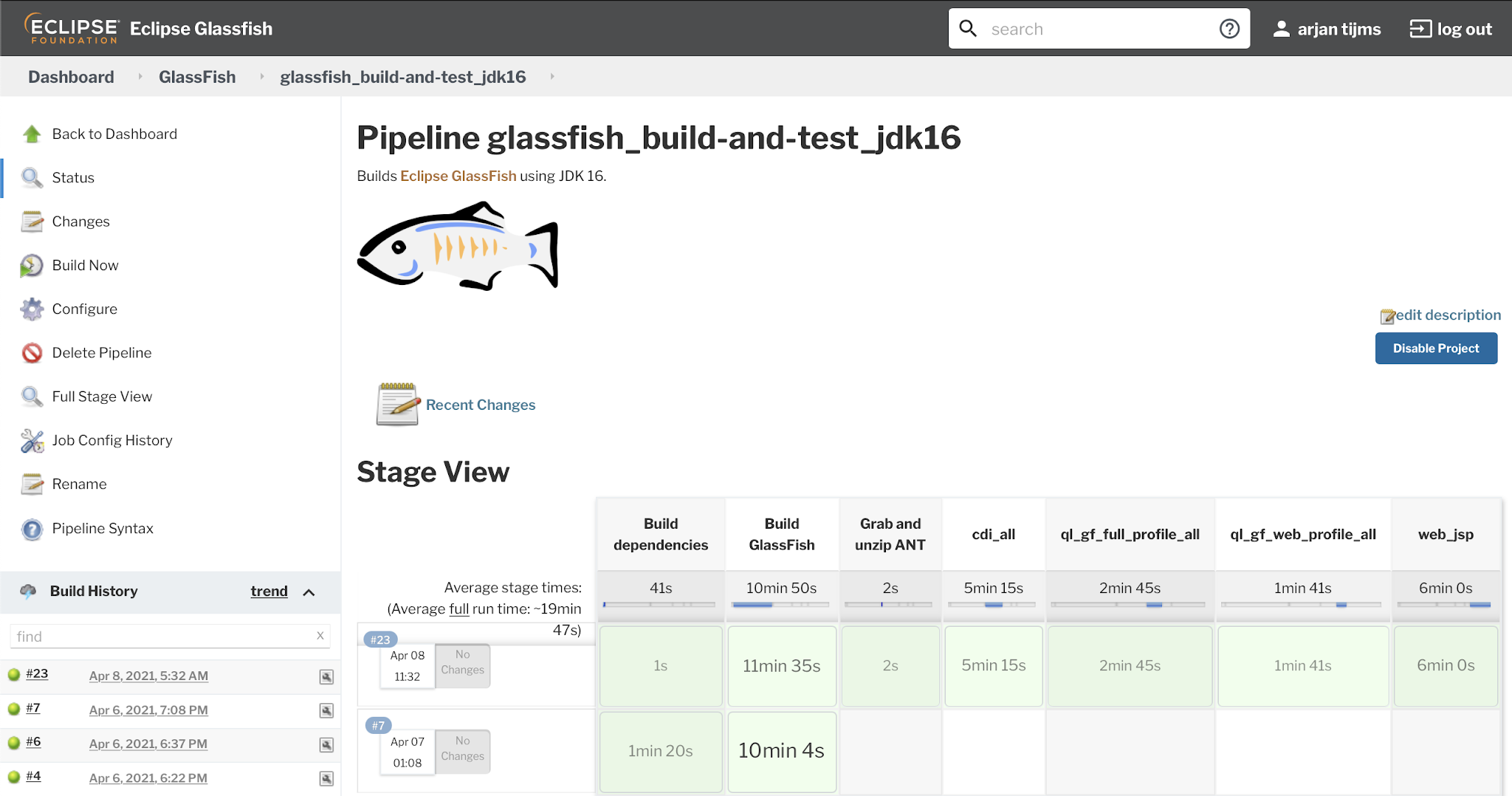
GlassFish , an open source Jakarta EE Platform implementation, is a code base that goes back a long time, in essence all the way back to 1996. It's also a fairly large code base. Therefor it's not suprising perhaps that in all that time, it obtained some cruft between all those lines of code, which made it challenging to run on modern versions of the JDK. The last few months or so the GlassFish team has been working on removing this cruft, and making the release compatible with newer JDK versions. The primary target was to be able to compile the code with JDK 11 and be able to run it on that as well. A stretch goal was to have it compiling with- and running on JDK 16 too. As of PR 23446 we have now reached this goal: Note that it concerns a nightly of a not-yet merged PR, and that the official certification of the soon to be released GlassFish 6.1.0 will be done against JDK 11 only (since, for now, the Jakarta EE TCK only runs on JDK 11). The internal tests touch a ...